mirror of
https://gitee.com/mymagicpower/AIAS.git
synced 2024-11-25 16:05:33 +08:00
| .. | ||
| src | ||
| pom.xml | ||
| README_CN.md | ||
| README_EN.md | ||
| tokenizer_sdk.iml | ||
huggingface Tokenizer
https://github.com/deepjavalibrary/djl/blob/master/extensions/tokenizers/README.md
1. pom 配置
<dependency>
<groupId>ai.djl.huggingface</groupId>
<artifactId>tokenizers</artifactId>
<version>0.19.0</version>
</dependency>
2. 例子代码
private static final HuggingFaceTokenizer tokenizer;
# 声明
static {
try {
tokenizer =
HuggingFaceTokenizer.builder()
.optManager(manager)
.optPadding(true)
.optPadToMaxLength()
.optMaxLength(MAX_LENGTH)
.optTruncation(true)
.optTokenizerName("openai/clip-vit-large-patch14")
.build();
// sentence-transformers/msmarco-distilbert-dot-v5
// openai/clip-vit-large-patch14
// https://huggingface.co/sentence-transformers/msmarco-distilbert-dot-v5
// https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/tokenizer/tokenizer_config.json
} catch (IOException e) {
throw new RuntimeException(e);
}
}
# 使用
List<String> tokens = tokenizer.tokenize(prompt);
下面方法已废弃,仅用于学习参考,请使用上面的库及用法
Transformer的常用Tokenizer系列 - Java实现
这个sdk里包含了用于自然语言处理的tokenizer(分词器)。 切词输出的token序列,兼容huggingface(一个python实现的知名NLP库)。 java实现的Tokenizer有助于在java环境部署NLP模型。
包含的tokenizer如下:
- SimpleTokenizer
- BertTokenizer
- WordpieceTokenizer
- BertFullTokenizer
- ClipBPETokenizer
- GPT2Tokenizer(Todo)
Python transformer 常用tokenizer:
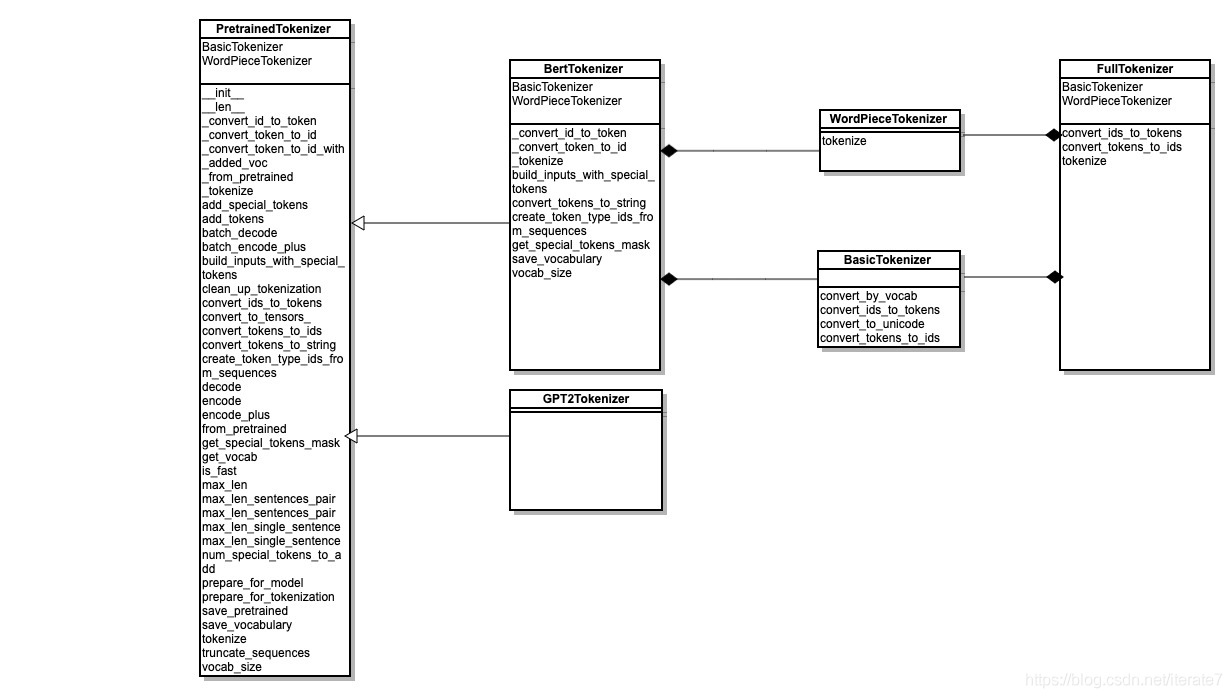
运行例子 - TokenizerExample
- 训练的例子代码:
@Test
public void testSimpleTokenizer() {
logger.info("testSimpleTokenizer:");
String input = "This tokenizer generates tokens for input sentence";
String delimiter = " ";
SimpleTokenizer tokenizer = new SimpleTokenizer(delimiter);
List<String> tokens = tokenizer.tokenize(input);
logger.info("Tokens: {}", tokens);
}
@Test
public void testBertTokenizer() {
logger.info("testBertTokenizer:");
String question = "When did Radio International start broadcasting?";
String paragraph = "Radio International was a general entertainment Channel. Which operated between December 1983 and April 2001";
BertTokenizer tokenizer = new BertTokenizer();
BertToken bertToken = tokenizer.encode(question, paragraph);
logger.info("Tokens: {}", bertToken.getTokens());
logger.info("TokenTypes: {}", bertToken.getTokenTypes());
logger.info("AttentionMask: {}", bertToken.getAttentionMask());
}
@Test
public void testWordpieceTokenizer() throws IOException {
logger.info("testWordpieceTokenizer:");
//replace vocab.txt with your vocabulary
Path filePath = Paths.get("src/test/resources/vocab.txt");
SimpleVocabulary vocabulary =
SimpleVocabulary.builder()
.optMinFrequency(1)
.addFromTextFile(filePath)
.optUnknownToken("[UNK]")
.build();
WordpieceTokenizer wordpieceTokenizer = new WordpieceTokenizer(vocabulary, "[UNK]", 200);
String input = "This tokenizer generates tokens for input sentence";
List<String> tokens = wordpieceTokenizer.tokenize(input);
logger.info("Tokens: {}", tokens);
}
@Test
public void testBertFullTokenizer() throws IOException {
logger.info("testBertFullTokenizer:");
//replace vocab.txt with your vocabulary
Path filePath = Paths.get("src/test/resources/vocab.txt");
SimpleVocabulary vocabulary =
SimpleVocabulary.builder()
.optMinFrequency(1)
.addFromTextFile(filePath)
.optUnknownToken("[UNK]")
.build();
//subword tokenizer
BertFullTokenizer tokenizer = new BertFullTokenizer(vocabulary, true);
String input = "This tokenizer generates tokens for input sentence";
List<String> tokens = tokenizer.tokenize(input);
logger.info("Tokens: {}", tokens);
}
@Test
public void testClipBPETokenizer() throws IOException, ModelException {
logger.info("testClipBPETokenizer:");
ClipBPETokenizer tokenizer = new ClipBPETokenizer("src/test/resources/bpe_simple_vocab_16e6.txt");
List<Integer> tokens = tokenizer.encode("we will test a diagram");
logger.info("Tokens: {}", tokens);
}
- 运行成功后,命令行应该看到下面的信息:
#BlazingText 测试文本:
[INFO ] - testSimpleTokenizer:
[INFO ] - Tokens: [This, tokenizer, generates, tokens, for, input, sentence]
[INFO ] - testBertTokenizer:
[INFO ] - Tokens: [[CLS], When, did, Radio, International, start, broadcasting, ?, [SEP], Radio, International, was, a, general, entertainment, Channel, ., Which, operated, between, December, 1983, and, April, 2001, [SEP]]
[INFO ] - TokenTypes: [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
[INFO ] - AttentionMask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
[INFO ] - testWordpieceTokenizer:
[INFO ] - Tokens: [[UNK], token, ##izer, generates, token, ##s, for, input, sentence]
[INFO ] - testBertFullTokenizer:
[INFO ] - Tokens: [this, token, ##izer, generates, token, ##s, for, input, sentence]
[INFO ] - testClipBPETokenizer:
[INFO ] - Tokens: [649, 751, 1628, 320, 22697]