| .dev_scripts | ||
| .github | ||
| asset | ||
| docs | ||
| examples/pytorch | ||
| requirements | ||
| resources | ||
| scripts | ||
| swift | ||
| tests | ||
| tools | ||
| .gitignore | ||
| .pre-commit-config_local.yaml | ||
| .pre-commit-config.yaml | ||
| CODE_OF_CONDUCT.md | ||
| CONTRIBUTING_CN.md | ||
| CONTRIBUTING.md | ||
| LICENSE | ||
| Makefile | ||
| MANIFEST.in | ||
| README_CN.md | ||
| README.md | ||
| requirements.txt | ||
| setup.cfg | ||
| setup.py | ||
SWIFT (Scalable lightWeight Infrastructure for Fine-Tuning)

ModelScope Community Website
中文 | English
![]()
![]()
![]()
![]()

![]()
📖 Table of Contents
📝 Introduction
SWIFT supports training(PreTraining/Fine-tuning/RLHF), inference, evaluation and deployment of 350+ LLMs and 100+ MLLMs (multimodal large models). Developers can directly apply our framework to their own research and production environments to realize the complete workflow from model training and evaluation to application. In addition to supporting the lightweight training solutions provided by PEFT, we also provide a complete Adapters library to support the latest training techniques such as NEFTune, LoRA+, LLaMA-PRO, etc. This adapter library can be used directly in your own custom workflow without our training scripts.
To facilitate use by users unfamiliar with deep learning, we provide a Gradio web-ui for controlling training and inference, as well as accompanying deep learning courses and best practices for beginners. SWIFT web-ui is available both on Huggingface space and ModelScope studio, please feel free to try!
SWIFT has rich documentations for users, please feel free to check our documentation website:
Paper | English Documentation | 中文文档
☎ Groups
You can contact us and communicate with us by adding our group:
| Discord Group | 微信群 |
|---|---|
 |
 |
🎉 News
- 2024.10.24: Support for training and deploying aya-expanse series models. Experience it using
swift infer --model_type aya-expanse-32b. - 2024.10.22: Support for training and deploying emu3-chat. Experience it using
swift infer --model_type emu3-chat. - 2024.10.22: Support for training and deploying molmo series models. Experience it using
swift infer --model_type molmo-7b-d. - 2024.10.09: Support for reward modeling for LLM and MLLM, as well as PPO training for LLM. Refer to the documentation.
- 2024.10.09: Support for training and deploying ovis1.6-gemma2 series models. Experience it using
swift infer --model_type ovis1_6-gemma2-9b. - 2024.09.26: Support for training and deploying llama3.2-vision series models. Experience it using
swift infer --model_type llama3_2-11b-vision-instruct. - 2024.09.26: Support for training and deploying llama3.2 series models. Experience it using
swift infer --model_type llama3_2-1b-instruct. - 2024.09.25: Support for training to deployment with got-ocr2. Best practices can be found here.
- 2024.09.24: Support for training and deploying llama3_1-8b-omni. Experience it using
swift infer --model_type llama3_1-8b-omni. - 2024.09.23: Support for training and deploying pixtral-12b. Experience it using
swift infer --model_type pixtral-12b --dtype fp16. - 🔥2024.09.19: Supports the qwen2.5, qwen2.5-math, and qwen2.5-coder series models. Supports the qwen2-vl-72b series models. Best practices can be found here.
- 2024.09.07: Support the
Reflection-llama3-70bmodel, use byswift sft/infer --model_type reflection-llama_3_1-70b. - 2024.09.06: Support fine-tuning and inference for mplug-owl3. Best practices can be found here.
- 2024.09.05: Support for the minicpm3-4b model. Experience it using
swift infer --model_type minicpm3-4b. - 2024.09.05: Support for the yi-coder series models. Experience it using
swift infer --model_type yi-coder-1_5b-chat. - 🔥2024.08.30: Support for inference and fine-tuning of the qwen2-vl series models: qwen2-vl-2b-instruct, qwen2-vl-7b-instruct. The best practices can be found here.
- 🔥2024.08.26: Support Liger, which supports models like LLaMA、Qwen、Mistral and so on, and reduce memory usage by 10%~60%, use
--use_liger trueto begin. - 🔥2024.08.22: Support
refttuner from ReFT to achieve 15×–65× more parameter-efficient than LoRA, use--sft_type reftto begin! - 🔥2024.08.21: Support for phi3_5-mini-instruct, phi3_5-moe-instruct, and phi3_5-vision-instruct. The best practices for fine-tuning Latex OCR using phi3_5-vision-instruct can be found here.
- 2024.08.21: Support for idefics3-8b-llama3, llava-onevision-qwen2-0_5b-ov, llava-onevision-qwen2-7b-ov, and llava-onevision-qwen2-72b-ov.
- 🔥2024.08.20: Support fine-tuning of multimodal large models using DeepSpeed-Zero3.
- 2024.08.20: Supported models: longwriter-glm4-9b, longwriter-llama3_1-8b. Supported dataset: longwriter-6k.
- 🔥2024.08.12: 🎉 SWIFT paper has been published to arXiv. Check this link to read.
- 🔥2024.08.12: Support packing with flash-attention without the contamination of attention_mask, use
--packingto begin. CheckPR. - 🔥2024.08.09: Support for inference and fine-tuning of the qwen2-audio model. Best practice can be found here.
- 🔥2024.08.08: Supports the qwen2-math series models: 1.5B, 7B, 72B. Use
swift infer --model_type qwen2-math-1_5b-instructfor an experience. - 🔥2024.08.07: Support for using vLLM for accelerating inference and deployment of multimodal large models such as the llava series and phi3-vision models. You can refer to the Multimodal & vLLM Inference Acceleration Documentation for more information.
- 2024.08.06: Support for minicpm-v-v2_6-chat is available. You can use
swift infer --model_type minicpm-v-v2_6-chatfor inference experience. Best practices can be found here. - 2024.08.06: Supports internlm2.5 series of 1.8b and 20b. Experience it using
swift infer --model_type internlm2_5-1_8b-chat. - 🔥2024.08.05: Support evaluation for multi-modal models! Same command with new datasets.
- 🔥2024.08.02: Support Fourier Ft. Use
--sft_type fourierftto begin, Check parameter documentation here. - 🔥2024.07.29: Support the use of lmdeploy for inference acceleration of LLM and VLM models. Documentation can be found here.
- 🔥2024.07.24: Support DPO/ORPO/SimPO/CPO alignment algorithm for vision MLLM, training scripts can be find in Document. support RLAIF-V dataset.
- 🔥2024.07.24: Support using Megatron for CPT and SFT on the Qwen2 series. You can refer to the Megatron training documentation.
- 🔥2024.07.24: Support for the llama3.1 series models, including 8b, 70b, and 405b. Support for openbuddy-llama3_1-8b-chat.
More
-
2024.07.20: Support mistral-nemo series models. Use
--model_type mistral-nemo-base-2407and--model_type mistral-nemo-instruct-2407to begin. -
2024.07.19: Support Q-Galore, this algorithm can reduce the training memory cost by 60% (qwen-7b-chat, full, 80G -> 35G), use
swift sft --model_type xxx --use_galore true --galore_quantization trueto begin! -
2024.07.17: Support newly released InternVL2 models:
model_typeare internvl2-1b, internvl2-40b, internvl2-llama3-76b. For best practices, refer to here. -
2024.07.17: Support the training and inference of NuminaMath-7B-TIR. Use with model_type
numina-math-7b. -
🔥2024.07.16: Support exporting for ollama and bitsandbytes. Use
swift export --model_type xxx --to_ollama trueorswift export --model_type xxx --quant_method bnb --quant_bits 4 -
2024.07.08: Support cogvlm2-video-13b-chat. You can check the best practice here.
-
2024.07.08: Support internlm-xcomposer2_5-7b-chat. You can check the best practice here.
-
🔥2024.07.06: Support for the llava-next-video series models: llava-next-video-7b-instruct, llava-next-video-7b-32k-instruct, llava-next-video-7b-dpo-instruct, llava-next-video-34b-instruct. You can refer to llava-video best practice for more information.
-
🔥2024.07.06: Support InternVL2 series: internvl2-2b, internvl2-4b, internvl2-8b, internvl2-26b.
-
2024.07.06: Support codegeex4-9b-chat.
-
2024.07.04: Support internlm2_5-7b series: internlm2_5-7b, internlm2_5-7b-chat, internlm2_5-7b-chat-1m.
-
2024.07.02: Support for
llava1_6-vicuna-7b-instruct,llava1_6-vicuna-13b-instructand other llava-hf models. For best practices, refer to here. -
🔥2024.06.29: Support eval-scope&open-compass for evaluation! Now we have supported over 50 eval datasets like
BoolQ, ocnli, humaneval, math, ceval, mmlu, gsk8k, ARC_e, please check our Eval Doc to begin! Next sprint we will support Multi-modal and Agent evaluation, remember to follow us : ) -
🔥2024.06.28: Support for Florence series model! See document
-
🔥2024.06.28: Support for Gemma2 series models: gemma2-9b, gemma2-9b-instruct, gemma2-27b, gemma2-27b-instruct.
-
🔥2024.06.18: Supports DeepSeek-Coder-v2 series model! Use model_type
deepseek-coder-v2-instructanddeepseek-coder-v2-lite-instructto begin. -
🔥2024.06.16: Supports KTO and CPO training! See document to start training!
-
2024.06.11: Support for tool-calling agent deployment that conform to the OpenAI interface.You can refer to Agent deployment best practice
-
🔥2024.06.07: Support Qwen2 series LLM, including Base and Instruct models of 0.5B, 1.5B, 7B, and 72B, as well as corresponding quantized versions gptq-int4, gptq-int8, and awq-int4. The best practice for self-cognition fine-tuning, inference and deployment of Qwen2-72B-Instruct using dual-card 80GiB A100 can be found here.
-
🔥2024.06.05: Support for glm4 series LLM and glm4v-9b-chat MLLM. You can refer to glm4v best practice.
-
🔥2024.06.01: Supports SimPO training! See document to start training!
-
🔥2024.06.01: Support for deploying large multimodal models, please refer to the Multimodal Deployment Documentation for more information.
-
2024.05.31: Supports Mini-Internvl model, Use model_type
mini-internvl-chat-2b-v1_5andmini-internvl-chat-4b-v1_5to train. -
2024.05.24: Supports Phi3-vision model, Use model_type
phi3-vision-128k-instructto train. -
2024.05.22: Supports DeepSeek-V2-Lite series models, model_type are
deepseek-v2-liteanddeepseek-v2-lite-chat -
2024.05.22: Supports TeleChat-12B-v2 model with quantized version, model_type are
telechat-12b-v2andtelechat-12b-v2-gptq-int4 -
🔥2024.05.21: Inference and fine-tuning support for MiniCPM-Llama3-V-2_5 are now available. For more details, please refer to minicpm-v-2.5 Best Practice.
-
🔥2024.05.20: Support for inferencing and fine-tuning cogvlm2-llama3-chinese-chat-19B, cogvlm2-llama3-chat-19B. you can refer to cogvlm2 Best Practice.
-
🔥2024.05.17: Support peft=0.11.0. Meanwhile support 3 new tuners:
BOFT,VeraandPissa. use--sft_type boft/verato use BOFT or Vera, use--init_lora_weights pissawith--sft_type lorato use Pissa. -
2024.05.16: Supports Llava-Next (Stronger) series models. For best practice, you can refer to here.
-
🔥2024.05.13: Support Yi-1.5 series models,use
--model_type yi-1_5-9b-chatto begin! -
2024.05.11: Support for qlora training and quantized inference using hqq and eetq. For more information, see the LLM Quantization Documentation.
-
2024.05.10: Support split a sequence to multiple GPUs to reduce memory usage. Use this feature by
pip install .[seq_parallel], then add--sequence_parallel_size nto your DDP script to begin! -
2024.05.08: Support DeepSeek-V2-Chat model, you can refer to this script.Support InternVL-Chat-V1.5-Int8 model, for best practice, you can refer to here.
-
🔥2024.05.07: Supoprts ORPO training! See document to start training!
-
2024.05.07: Supports Llava-Llama3 model from xtuner,model_type is
llava-llama-3-8b-v1_1. -
2024.04.29: Supports inference and fine-tuning of InternVL-Chat-V1.5 model. For best practice, you can refer to here.
-
🔥2024.04.26: Support LISA and unsloth training! Specify
--lisa_activated_layers=2to use LISA(to reduce the memory cost to 30 percent!), specify--tuner_backend unslothto use unsloth to train a huge model(full or lora) with lesser memory(30 percent or lesser) and faster speed(5x)! -
🔥2024.04.26: Support the fine-tuning and inference of Qwen1.5-110B and Qwen1.5-110B-Chat model, use this script to start training!
-
2024.04.24: Support for inference and fine-tuning of Phi3 series models. Including: phi3-4b-4k-instruct, phi3-4b-128k-instruct.
-
2024.04.22: Support for inference, fine-tuning, and deployment of chinese-llama-alpaca-2 series models. This includes:chinese-llama-2-1.3b, chinese-llama-2-7b, chinese-llama-2-13b, chinese-alpaca-2-1.3b, chinese-alpaca-2-7b and chinese-alpaca-2-13b along with their corresponding 16k and 64k long text versions.
-
2024.04.22: Support for inference and fine-tuning of Llama3 GPTQ-Int4, GPTQ-Int8, and AWQ series models. Support for inference and fine-tuning of chatglm3-6b-128k, Openbuddy-Llama3.
-
2024.04.20: Support for inference, fine-tuning, and deployment of Atom series models. This includes: Atom-7B and Atom-7B-Chat. use this script to train.
-
2024.04.19: Support for single-card, DDP, ZeRO2, and ZeRO3 training and inference with NPU, please refer to NPU Inference and Fine-tuning Best Practice.
-
2024.04.19: Support for inference, fine-tuning, and deployment of Llama3 series models. This includes: Llama-3-8B, Llama-3-8B-Instruct, Llama-3-70B, and Llama-3-70B-Instruct. use this script to train.
-
2024.04.18: Supported models: wizardlm2-7b-awq, wizardlm2-8x22b, yi-6b-chat-awq, yi-6b-chat-int8, yi-34b-chat-awq, yi-34b-chat-int8. Supported
--deepspeed zero3-offloadand provided default zero3-offload configuration file for zero3+cpu offload usage. -
2024.04.18: Supported compatibility with HuggingFace ecosystem using the environment variable
USE_HF, switching to use models and datasets from HF. Please refer to the HuggingFace ecosystem compatibility documentation. -
2024.04.17: Support the evaluation for OpenAI standard interfaces. Check the parameter documentation for details.
-
🔥2024.04.17: Support CodeQwen1.5-7B series: CodeQwen1.5-7B, CodeQwen1.5-7B-Chat,CodeQwen1.5-7B-Chat-AWQ, use this script to train.
-
2024.04.16: Supports inference and fine-tuning of llava-v1.6-34b model. For best practice, you can refer to here.
-
2024.04.13: Support the fine-tuning and inference of Mixtral-8x22B-v0.1 model, use this script to start training!
-
2024.04.13: Support the newly launched MiniCPM series: MiniCPM-V-2.0、MiniCPM-2B-128k、MiniCPM-MoE-8x2B and MiniCPM-1B.use this script to start training!
-
🔥2024.04.11: Support Model Evaluation with MMLU/ARC/CEval datasets(also user custom eval datasets) with one command! Check this documentation for details. Meanwhile, we support a trick way to do multiple ablation experiments, check this documentation to use.
-
🔥2024.04.11: Support c4ai-command-r series: c4ai-command-r-plus, c4ai-command-r-v01, use this script to train.
-
2024.04.10: Use SWIFT to fine-tune the qwen-7b-chat model to enhance its function call capabilities, and combine it with Modelscope-Agent for best practices, which can be found here.
-
🔥2024.04.09: Support ruozhiba dataset. Search
ruozhibain this documentation to begin training! -
2024.04.08: Support the fine-tuning and inference of XVERSE-MoE-A4.2B model, use this script to start training!
-
2024.04.04: Support QLoRA+FSDP to train a 70B model with two 24G memory GPUs, use this script to train.
-
🔥2024.04.03: Support Qwen1.5-32B series: Qwen1.5-32B, Qwen1.5-32B-Chat, Qwen1.5-32B-Chat-GPTQ-Int4.use this script to start training!
-
🔥2024.04.02: Support the fine-tuning and inference of Mengzi3-13B-Base model, use this script to start training!
-
🔥2024.04.01: Support dbrx series: dbrx-base and dbrx-instruct, use this script to start training!
-
🔥2024.03.29: Support Qwen1.5-MoE series: Qwen1.5-MoE-A2.7B, Qwen1.5-MoE-A2.7B-Chat, Qwen1.5-MoE-A2.7B-Chat-GPTQ-Int4.
-
🔥2024.03.29: Support the fine-tuning and inference of Grok-1 300B MoE, please view details here.
-
🔥2024.03.25: Supports inference and fine-tuning of TeleChat-7b and TeleChat-12b model, use this script to start training!
-
🔥2024.03.20: Supports inference and fine-tuning for the llava series. For best practice, you can refer to here.
-
🔥2024.03.12: Support inference and fine-tuning for deepseek-vl series. Best practices can be found here.
-
🔥2024.03.11: Support GaLore for effectively reducing memory usage to 1/2 of the original in full-parameter training.
-
🔥2024.03.10: End-to-end best practices from fine-tuning to deployment for Qwen1.5-7B-Chat and Qwen1.5-72B-Chat.
-
🔥2024.03.09: Support training and inference of MAMBA model, use this script to start training!
-
2024.03.09: Support training and inference of AQLM quantized model, use this script to start training!
-
2024.03.06: Support training and inference of AWQ quantized model, use this Qwen1.5-AWQ model script to start training, and support training and inference of yi-9b.
-
🔥2024.02.29: Support LLaMA PRO, simply use this script to start training.
-
🔥2024.02.29: Support LoRA+, simply use this script to start training.
-
2024.02.25: Support
swift exportto quantize models using AWQ/GPTQ and push to ModelScope Hub. See documentation: LLM Quantization. -
2024.02.22: Support gemma series: gemma-2b, gemma-2b-instruct, gemma-7b, gemma-7b-instruct.
-
2024.02.16: Support deepseek-math series: deepseek-math-7b, deepseek-math-7b-instruct, deepseek-math-7b-chat.
-
🔥2024.02.05: Support Qwen1.5 series models, see model list for all supported Qwen1.5 models. Provide fine-tuning scripts for qwen1half-7b-chat, qwen1half-7b-chat-int8.
-
2024.02.05: Support training of diffusion models such as SDXL, SD, ControlNet, as well as DreamBooth training. See corresponding training scripts for details.
-
2024.02.01: Support minicpm series: minicpm-2b-sft-chat, minicpm-2b-chat.
-
🔥2024.02.01: Support dataset mixing to reduce catastrophic forgetting. Use
--train_dataset_mix_ratio 2.0to enable training! We also open sourced the general knowledge dataset ms-bench. -
🔥2024.02.01: Support Agent training! Agent training algorithm is derived from this paper. We also added ms-agent, a high-quality agent dataset. Use this script to start Agent training!
-
🔥2024.02.01: Support adding SFT loss in DPO training to reduce repetitive generation caused by KL divergence loss.
-
2024.02.01: Support using AdaLoRA and IA3 adapters in training.
-
2024.02.01: Support
--merge_loraparameter in AnimateDiff training. -
2024.01.30: Support internlm-xcomposer2-7b-chat.
-
🔥2024.01.30: Support ZeRO-3, simply specify
--deepspeed default-zero3. -
2024.01.29: Support internlm2-math series: internlm2-math-7b, internlm2-math-7b-chat, internlm2-math-20b, internlm2-math-20b-chat.
-
🔥2024.01.26: Support yi-vl-6b-chat, yi-vl-34b-chat.
-
2024.01.24: Support codefuse-codegeex2-6b-chat, codefuse-qwen-14b-chat.
-
2024.01.23: Support orion series: orion-14b, orion-14b-chat.
-
2024.01.20: Support xverse-13b-256k, xverse-65b-v2, xverse-65b-chat.
-
🔥2024.01.17: Support internlm2 series: internlm2-7b-base, internlm2-7b, internlm2-7b-sft-chat, internlm2-7b-chat, internlm2-20b-base, internlm2-20b, internlm2-20b-sft-chat, internlm2-20b-chat.
-
2024.01.15: Support yuan series: yuan2-2b-instruct, yuan2-2b-janus-instruct, yuan2-51b-instruct, yuan2-102b-instruct.
-
🔥2024.01.12: Support deepseek-moe series: deepseek-moe-16b, deepseek-moe-16b-chat.
-
🔥2024.01.04: Support VLLM deployment, compatible with OpenAI API style, see VLLM Inference Acceleration and Deployment for details.
-
2024.01.04: Update Benchmark for convenient viewing of training speed and memory usage of different models.
-
🔥2023.12.29: Support web-ui for sft training and inference, use
swift web-uiafter installing ms-swift to start. -
🔥2023.12.29: Support DPO RLHF (Reinforcement Learning from Human Feedback) and three datasets for this task: AI-ModelScope/stack-exchange-paired, AI-ModelScope/hh-rlhf and AI-ModelScope/hh_rlhf_cn. See documentation to start training!
-
🔥2023.12.28: Support SCEdit! This tuner can significantly reduce memory usage in U-Net and support low-memory controllable image generation (replacing ControlNet), read the section below to learn more.
-
2023.12.23: Support codegeex2-6b.
-
2023.12.19: Support phi2-3b.
-
2023.12.18: Support VLLM for inference acceleration.
-
2023.12.15: Support deepseek, deepseek-coder series: deepseek-7b, deepseek-7b-chat, deepseek-67b, deepseek-67b-chat, openbuddy-deepseek-67b-chat, deepseek-coder-1_3b, deepseek-coder-1_3b-instruct, deepseek-coder-6_7b, deepseek-coder-6_7b-instruct, deepseek-coder-33b, deepseek-coder-33b-instruct.
-
2023.12.13: Support mistral-7b-instruct-v2, mixtral-moe-7b, mixtral-moe-7b-instruct.
-
2023.12.09: Support
freeze_parameters_ratioparameter as a compromise between lora and full-parameter training. Corresponding sh can be found in full_freeze_ddp. Supportdisable_tqdm,lazy_tokenize,preprocess_num_procparameters, see command line arguments for details. -
2023.12.08: Support sus-34b-chat, support yi-6b-200k, yi-34b-200k.
-
2023.12.07: Support Multi-Node DDP training.
-
2023.12.05: Support models: zephyr-7b-beta-chat, openbuddy-zephyr-7b-chat. Support datasets: hc3-zh, hc3-en.
-
🔥2023.12.02: Self-cognition fine-tuning best practices, 10 minutes to fine-tune a large model for self-cognition, create your own unique large model.
-
🔥2023.11.30: Support training and inference of qwen-1_8b, qwen-72b, qwen-audio series models. Corresponding sh scripts can be found in qwen_1_8b_chat, qwen_72b_chat, qwen_audio_chat
-
🔥2023.11.29: Support training and inference of AnimateDiff
-
🔥2023.11.24: Support yi-34b-chat, codefuse-codellama-34b-chat models. Corresponding sh scripts can be found in yi_34b_chat, codefuse_codellama_34b_chat.
-
🔥2023.11.18: Support tongyi-finance-14b series models: tongyi-finance-14b, tongyi-finance-14b-chat, tongyi-finance-14b-chat-int4. Corresponding sh scripts can be found in tongyi_finance_14b_chat_int4.
-
2023.11.16: Support flash attn for more models: qwen series, qwen-vl series, llama series, openbuddy series, mistral series, yi series, ziya series. Please use
use_flash_attnparameter. -
🔥2023.11.11: Support NEFTune, simply use
Swift.prepare_model(model, NEFTuneConfig())to enable. -
🔥2023.11.11: Support training and inference by command line and inference by Web-UI, see
Usage with Swift CLIsection below for details. -
🔥2023.11.10: Support bluelm series models: bluelm-7b, bluelm-7b-chat, bluelm-7b-32k, bluelm-7b-chat-32k. Corresponding sh scripts can be found in bluelm_7b_chat.
-
🔥2023.11.08: Support training and inference of xverse-65b model, script at xverse_65b.
-
🔥2023.11.07: Support training and inference of yi-6b, yi-34b models, scripts at yi_6b, yi_34b.
-
🔥2023.10.30: Support two new tuners: QA-LoRA and LongLoRA.
-
🔥2023.10.30: Support editing models using ROME (Rank One Model Editing) to infuse new knowledge into models without training!
-
2023.10.30: Support skywork-13b series models: skywork-13b, skywork-13b-chat. Corresponding sh scripts can be found in skywork_13b.
-
🔥2023.10.27: Support chatglm3 series models: chatglm3-6b-base, chatglm3-6b, chatglm3-6b-32k. Corresponding sh scripts can be found in chatglm3_6b.
-
🔥2023.10.17: Support SFT of int4, int8 models: qwen-7b-chat-int4, qwen-14b-chat-int4, qwen-vl-chat-int4, baichuan2-7b-chat-int4, baichuan2-13b-chat-int4, qwen-7b-chat-int8, qwen-14b-chat-int8.
-
2023.10.15: Support ziya2-13b series models: ziya2-13b, ziya2-13b-chat.
-
2023.10.12: Support mistral-7b series models: openbuddy-mistral-7b-chat, mistral-7b, mistral-7b-instruct.
-
🔥2023.10.07: Support DeepSpeed ZeRO-2, enabling lora (not just qlora) to run DDP on dual A10 cards.
-
2023.10.04: Support more math, law, SQL, code domain datasets: blossom-math-zh, school-math-zh, text2sql-en, sql-create-context-en, lawyer-llama-zh, tigerbot-law-zh, leetcode-python-en.
-
🔥2023.09.25: Support qwen-14b series: qwen-14b, qwen-14b-chat.
-
2023.09.18: Support internlm-20b series: internlm-20b, internlm-20b-chat.
-
2023.09.12: Support MP+DDP to accelerate full-parameter training.
-
2023.09.05: Support openbuddy-llama2-70b-chat.
-
2023.09.03: Support baichuan2 series: baichuan2-7b, baichuan2-7b-chat, baichuan2-13b, baichuan2-13b-chat.
🛠️ Installation
SWIFT runs in the Python environment. Please ensure your Python version is higher than 3.8.
- Method 1: Install SWIFT using pip command:
# Full capabilities
pip install 'ms-swift[all]' -U
# LLM only
pip install 'ms-swift[llm]' -U
# AIGC only
pip install 'ms-swift[aigc]' -U
# Adapters only
pip install ms-swift -U
- Method 2: Install SWIFT through source code (convenient for running training and inference scripts), please run the following commands:
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e '.[llm]'
SWIFT depends on torch>=1.13, recommend torch>=2.0.0.
- Method 3: Use SWIFT in our Docker image
🚀 Getting Started
This section introduces basic usage, see the Documentation section for more ways to use.
Web-UI
Web-UI is a gradio-based interface for zero-threshold training and deployment. It is easy to use and perfectly supports multi-GPU training and deployment:
SWIFT_UI_LANG=en swift web-ui
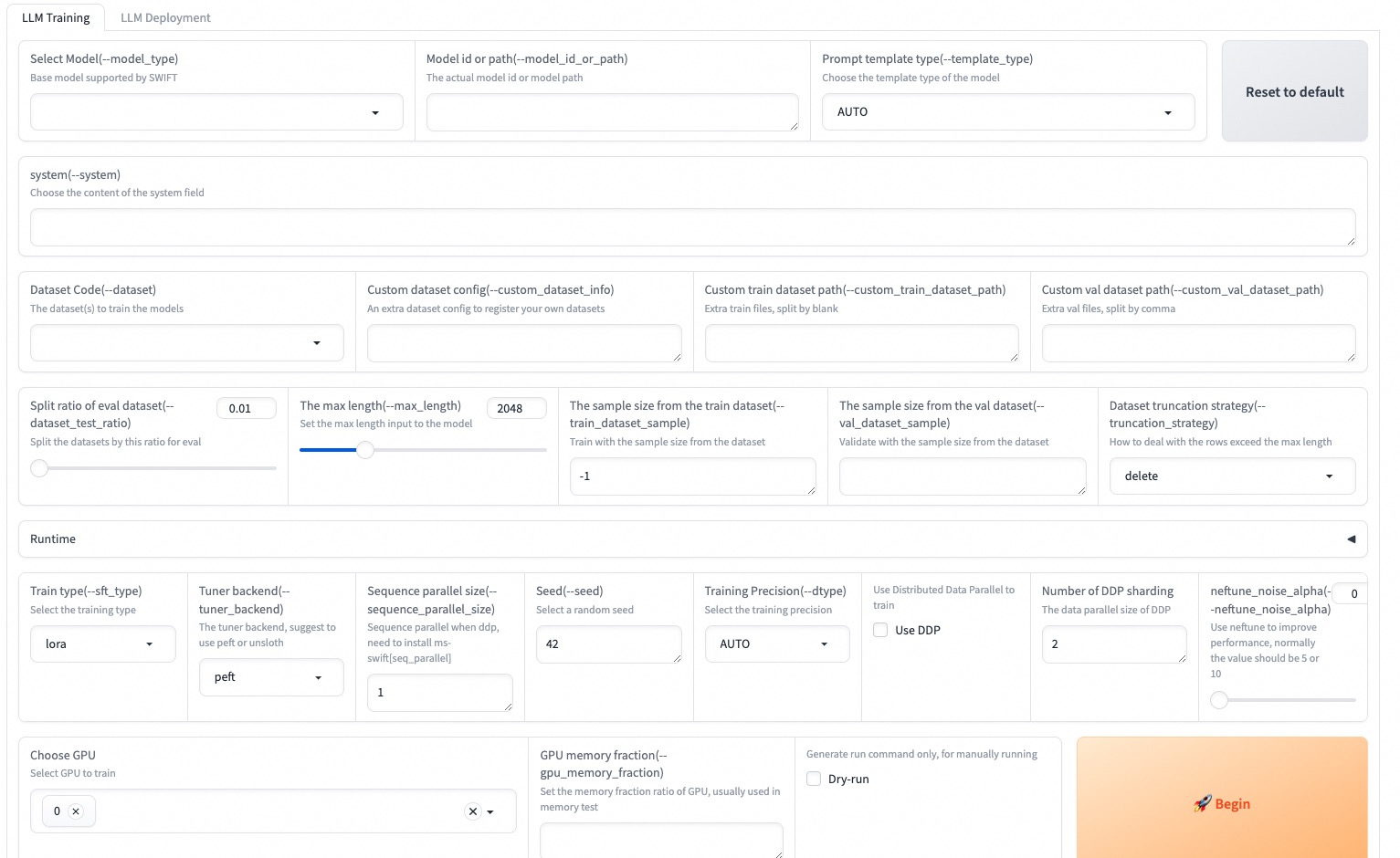
Training
Training Scripts
You can refer to the following scripts to customize your own training script.
- full: qwen1half-7b-chat (A100), qwen-7b-chat (2*A100)
- full+ddp+zero2: qwen-7b-chat (4*A100)
- full+ddp+zero3: qwen-14b-chat (4*A100)
- lora: chatglm3-6b (3090), baichuan2-13b-chat (2*3090), yi-34b-chat (A100), qwen-72b-chat (2*A100)
- lora+ddp: chatglm3-6b (2*3090)
- lora+ddp+zero3: qwen-14b-chat (4*3090), qwen-72b-chat (4*A100)
- qlora(gptq-int4): qwen-7b-chat-int4 (3090)
- qlora(gptq-int8): qwen1half-7b-chat-int8 (3090)
- qlora(bnb-int4): qwen-7b-chat (3090)
Supported Training Processes
| Training Process | Training Method |
|---|---|
| Pretraining | Text Generation |
| Fine-tuning | Single-turn/Multi-turn Agent Training/Self-cognition Multi-modal Vision/Multi-modal Speech |
| Human Alignment | DPO ORPO SimPO CPO KTO |
| Text-to-Image | DreamBooth, etc. |
| Text-to-Video | - |
Single GPU Training
Start single GPU fine-tuning with the following command:
LoRA:
# Experimental Environment: A100
# GPU Memory Requirement: 20GB
# Runtime: 3.1 hours
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model_type qwen1half-7b-chat \
--dataset blossom-math-zh \
--num_train_epochs 5 \
--sft_type lora \
--output_dir output \
--eval_steps 200 \
Full-parameter:
# Experimental Environment: A100
# GPU Memory Requirement: 80GB
# Runtime: 2.5 hours
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model_type qwen1half-7b-chat \
--dataset blossom-math-zh \
--num_train_epochs 5 \
--sft_type full \
--output_dir output \
--eval_steps 500 \
Model Parallel Training
# Experimental Environment: 2 * A100
# GPU Memory Requirement: 10GB + 13GB
# Runtime: 3.4 hours
CUDA_VISIBLE_DEVICES=0,1 \
swift sft \
--model_type qwen1half-7b-chat \
--dataset blossom-math-zh \
--num_train_epochs 5 \
--sft_type lora \
--output_dir output \
Data Parallel Training
# Experimental Environment: 4 * A100
# GPU Memory Requirement: 4 * 30GB
# Runtime: 0.8 hours
NPROC_PER_NODE=4 \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift sft \
--model_type qwen1half-7b-chat \
--dataset blossom-math-zh \
--num_train_epochs 5 \
--sft_type lora \
--output_dir output \
Combining Model Parallelism and Data Parallelism:
# Experimental Environment: 4 * A100
# GPU Memory Requirement: 2*14GB + 2*18GB
# Runtime: 1.7 hours
NPROC_PER_NODE=2 \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift sft \
--model_type qwen1half-7b-chat \
--dataset blossom-math-zh \
--num_train_epochs 5 \
--sft_type lora \
--output_dir output \
Deepspeed Training
Deepspeed supports training of quantized GPTQ and AWQ models.
ZeRO2:
# Experimental Environment: 4 * A100
# GPU Memory Requirement: 4 * 21GB
# Runtime: 0.9 hours
NPROC_PER_NODE=4 \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift sft \
--model_type qwen1half-7b-chat \
--dataset blossom-math-zh \
--num_train_epochs 5 \
--sft_type lora \
--output_dir output \
--deepspeed default-zero2 \
ZeRO3:
# Experimental Environment: 4 * A100
# GPU Memory Requirement: 4 * 19GB
# Runtime: 3.2 hours
NPROC_PER_NODE=4 \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift sft \
--model_type qwen1half-7b-chat \
--dataset blossom-math-zh \
--num_train_epochs 5 \
--sft_type lora \
--output_dir output \
--deepspeed default-zero3 \
ZeRO3-Offload:
# Experimental Environment: 4 * A100
# GPU Memory Requirement: 4 * 12GB
# Runtime: 60 hours
NPROC_PER_NODE=4 \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift sft \
--model_id_or_path AI-ModelScope/WizardLM-2-8x22B \
--dataset blossom-math-zh \
--num_train_epochs 5 \
--sft_type lora \
--output_dir output \
--deepspeed zero3-offload \
Multi-node Multi-GPU
# If the disk is not shared, please additionally specify `--save_on_each_node true` in the shell scripts on each machine.
# node0
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
NNODES=2 \
NODE_RANK=0 \
MASTER_ADDR=127.0.0.1 \
NPROC_PER_NODE=8 \
swift sft \
--model_type qwen1half-32b-chat \
--sft_type full \
--dataset blossom-math-zh \
--output_dir output \
--deepspeed default-zero3 \
# node1
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
NNODES=2 \
NODE_RANK=1 \
MASTER_ADDR=xxx.xxx.xxx.xxx \
NPROC_PER_NODE=8 \
swift sft \
--model_type qwen1half-32b-chat \
--sft_type full \
--dataset blossom-math-zh \
--output_dir output \
--deepspeed default-zero3 \
AliYun-DLC multi-node training
In DLC product, WORLD_SIZE is the node number, RANK is the node index, this is different from the definition of torchrun.
NNODES=$WORLD_SIZE \
NODE_RANK=$RANK \
swift sft \
--model_type qwen1half-32b-chat \
--sft_type full \
--dataset blossom-math-zh \
--output_dir output \
--deepspeed default-zero3
Pretraining
# Experimental Environment: 4 * A100
# GPU Memory Requirement: 4 * 30GB
# Runtime: 0.8 hours
NPROC_PER_NODE=4 \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift pt \
--model_type qwen1half-7b \
--dataset chinese-c4#100000 \
--num_train_epochs 1 \
--sft_type full \
--deepspeed default-zero3 \
--output_dir output \
--lazy_tokenize true
RLHF
# We support rlhf_type dpo/cpo/simpo/orpo/kto
CUDA_VISIBLE_DEVICES=0 \
swift rlhf \
--rlhf_type dpo \
--model_type qwen1half-7b-chat \
--dataset shareai-llama3-dpo-zh-en-emoji \
--num_train_epochs 5 \
--sft_type lora \
--output_dir output \
Inference
Original model:
CUDA_VISIBLE_DEVICES=0 swift infer --model_type qwen1half-7b-chat
# use VLLM
CUDA_VISIBLE_DEVICES=0 swift infer --model_type qwen1half-7b-chat \
--infer_backend vllm --max_model_len 8192
LoRA fine-tuned:
CUDA_VISIBLE_DEVICES=0 swift infer --ckpt_dir xxx/checkpoint-xxx --load_dataset_config true
# use VLLM
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir xxx/checkpoint-xxx --load_dataset_config true \
--merge_lora true --infer_backend vllm --max_model_len 8192
Evaluation
Original model:
CUDA_VISIBLE_DEVICES=0 swift eval --model_type qwen1half-7b-chat \
--eval_dataset ARC_c --infer_backend vllm
LoRA fine-tuned:
CUDA_VISIBLE_DEVICES=0 swift eval --ckpt_dir xxx/checkpoint-xxx \
--eval_dataset ARC_c --infer_backend vllm \
--merge_lora true \
Quantization
Original model:
CUDA_VISIBLE_DEVICES=0 swift export --model_type qwen1half-7b-chat \
--quant_bits 4 --quant_method awq
LoRA fine-tuned:
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir xxx/checkpoint-xxx --load_dataset_config true \
--quant_method awq --quant_bits 4 \
--merge_lora true \
Deployment
The client uses the OpenAI API for invocation, for details refer to the LLM deployment documentation.
Original model:
CUDA_VISIBLE_DEVICES=0 swift deploy --model_type qwen1half-7b-chat
# 使用VLLM加速
CUDA_VISIBLE_DEVICES=0 swift deploy --model_type qwen1half-7b-chat \
--infer_backend vllm --max_model_len 8192
LoRA fine-tuned:
CUDA_VISIBLE_DEVICES=0 swift deploy --ckpt_dir xxx/checkpoint-xxx
# 使用VLLM加速
CUDA_VISIBLE_DEVICES=0 swift deploy \
--ckpt_dir xxx/checkpoint-xxx --merge_lora true \
--infer_backend vllm --max_model_len 8192
Supported Models
The complete list of supported models and datasets can be found at Supported Models and Datasets List.
LLMs
| Model Type | Model Introduction | Language | Model Size | Model Type |
|---|---|---|---|---|
| Qwen Qwen1.5 Qwen2 Qwen2.5 |
Tongyi Qwen series models | Chinese English |
0.5B-110B including quantized versions |
base model chat model MoE model code model |
| ChatGLM2 ChatGLM3 Codegeex2 GLM4 Codegeex4 |
Zhipu ChatGLM series models | Chinese English |
6B-9B | base model chat model code model long text model |
| Baichuan Baichuan2 |
Baichuan 1 and Baichuan 2 | Chinese English |
7B-13B including quantized versions |
base model chat model |
| Yuan2 | Langchao Yuan series models | Chinese English |
2B-102B | instruct model |
| XVerse | XVerse series models | Chinese English |
7B-65B | base model chat model long text model MoE model |
| LLaMA2 | LLaMA2 series models | English | 7B-70B including quantized versions |
base model chat model |
| LLaMA3 LLaMA3.1 Llama3.2 |
LLaMA3 series models | English | 1B-70B including quantized versions |
base model chat model |
| Mistral Mixtral |
Mistral series models | English | 7B-22B | base model instruct model MoE model |
| Yi Yi1.5 Yi-Coder |
01AI's YI series models | Chinese English |
1.5B-34B including quantized |
base model chat model long text model |
| InternLM InternLM2 InternLM2-Math InternLM2.5 |
Pujiang AI Lab InternLM series models | Chinese English |
1.8B-20B | base model chat model math model |
| DeepSeek DeepSeek-MoE DeepSeek-Coder DeepSeek-Math DeepSeek-V2 DeepSeek-Coder-V2 |
DeepSeek series models | Chinese English |
1.3B-236B | base model chat model MoE model code model math model |
| MAMBA | MAMBA temporal convolution model | English | 130M-2.8B | base model |
| Gemma Gemma2 |
Google Gemma series models | English | 2B-27B | base model instruct model |
| MiniCPM MiniCPM3 |
OpenBmB MiniCPM series models | Chinese English |
2B-3B | chat model MoE model |
| OpenBuddy | OpenBuddy series models | Chinese English |
7B-70B | base model chat model |
| Orion | OrionStar AI series models | Chinese English |
14B | base model chat model |
| BlueLM | VIVO BlueLM large model | Chinese English |
7B | base model chat model |
| Ziya2 | Fengshenbang series models | Chinese English |
13B | base model chat model |
| Skywork | Skywork series models | Chinese English |
13B | base model chat model |
| Zephyr | Zephyr series models based on Mistral | English | 7B | chat model |
| PolyLM | Tongyi Lab self-developed PolyLM series models | Multilingual | 13B | base model |
| SeqGPT | Tongyi Lab self-developed text understanding model for information extraction and text classification | Chinese | 560M | semantic understanding model |
| SUS | Southern University of Science and Technology model fine-tuned on YI | Chinese English |
34B | chat model |
| Tongyi-Finance | Tongyi finance series models | Chinese English |
14B | base model chat model financial model |
| CodeFuse-CodeLLaMA CodeFuse-Codegeex2 CodeFuse-Qwen |
Ant CodeFuse series models | Chinese English |
6B-34B | chat model code model |
| phi2/phi3 | Microsoft's PHI series models | English | 3B/4B | base model instruct model code model |
| Grok | X-ai | English | 300B | base model |
| TeleChat | Tele-AI | Chinese English |
7B-12B | chat model |
| dbrx | databricks | English | 132B | base model chat model |
| mengzi3 | Langboat | Chinese English |
13B | base model |
| c4ai-command-r | c4ai | Multilingual | 35B-104B | chat model |
| aya-expanse | aya | Multilingual | 8B-32B | chat model |
| WizardLM2 | WizardLM2 series models | English | 7B-8x22B including quantized versions |
chat model MoE model |
| Atom | Atom | Chinese | 7B | base model chat model |
| Chinese-LLaMA-Alpaca-2 | Chinese-LLaMA-Alpaca-2 | Chinese | 1.3B-13B | base model chat model long text model |
| Chinese-LLaMA-Alpaca-3 | Chinese-LLaMA-Alpaca-3 | Chinese | 8B | base model chat model |
| ModelScope-Agent | ModelScope Agent series models | Chinese | 7B-14B | agent model |
| Numina | AI-MO | English | 7B | Math |
MLLMs
| Model Type | Model Introduction | Language | Model Size | Model Type |
|---|---|---|---|---|
| Qwen-VL Qwen2-VL |
Tongyi Qwen vision model | Chinese English |
2B-72B including quantized versions |
base model chat model |
| Qwen-Audio Qwen2-Audio |
Tongyi Qwen speech model | Chinese English |
7B | base model chat model |
| Llama3.2-Vision | Llama3.2 | English | 11B-90B | base model chat model |
| YI-VL | 01AI's YI series vision models | Chinese English |
6B-34B | chat model |
| XComposer2 XComposer2.5 |
Pujiang AI Lab InternLM vision model | Chinese English |
7B | chat model |
| DeepSeek-VL Deepseek-Janus |
DeepSeek series vision models | Chinese English |
1.3B-7B | chat model |
| MiniCPM-V MiniCPM-V-2 MiniCPM-V-2.5 MiniCPM-V-2.6 |
OpenBmB MiniCPM vision model | Chinese English |
3B-9B | chat model |
| CogVLM CogAgent CogVLM2 CogVLM2-Video GLM4V |
Zhipu ChatGLM visual QA and Agent model | Chinese English |
9B-19B | chat model |
| Llava-HF | Llava-HF series models | English | 0.5B-110B | chat model |
| Llava1.5 Llava1.6 |
Llava series models | English | 7B-34B | chat model |
| Llava-Next Llava-Next-Video |
Llava-Next series models | Chinese English |
7B-110B | chat model |
| mPLUG-Owl2 mPLUG-Owl2.1 mPLUG-Owl3 |
mPLUG-Owl series models | English | 1B-11B | chat model |
| InternVL Mini-InternVL InternVL2 |
InternVL | Chinese English |
1B-40B including quantized version |
chat model |
| Llava-llama3 | xtuner | English | 8B | chat model |
| Phi3-Vision | Microsoft | English | 4B | chat model |
| PaliGemma | English | 3B | chat model | |
| Florence | Microsoft | English | 0.23B-0.77B | chat model |
| Idefics3 | HuggingFaceM4 | English | 8B | chat model |
| Pixtral | mistralai | English | 12B | chat model |
| Llama3.1-Omni | LLaMA-Omni | English | 8B | chat model |
| Ovis | Ovis | English | 9B | chat model |
| Molmo | Molmo series models | English | 1B-72B | chat model |
| Emu3-Chat | Emu3-Chat | English | 8B | chat model |
Diffusion Models
| Model Type | Model Introduction | Language | Model Type |
|---|---|---|---|
| AnimateDiff | AnimateDiff animation model | English | text-to-video |
| SD1.5/SD2.0/SDXL | StabilityAI series diffusion models | English | text-to-image |
Supported Open Source Datasets
| Dataset Type | Training Task | Dataset |
|---|---|---|
| General | Fine-tuning | 🔥ruozhiba, 🔥ms-bench, 🔥alpaca-en(gpt4), 🔥alpaca-zh(gpt4), multi-alpaca, instinwild, cot-en, cot-zh, firefly-zh, instruct-en, gpt4all-en, sharegpt, tulu-v2-sft-mixture, wikipedia-zh, open-orca, sharegpt-gpt4, deepctrl-sft, coig-cqia. |
| Agent | Fine-tuning | 🔥ms-agent, 🔥ms-agent-for-agentfabric, ms-agent-multirole, 🔥toolbench-for-alpha-umi, damo-agent-zh, damo-agent-zh-mini, agent-instruct-all-en. |
| General | Human Alignment | hh-rlhf, 🔥hh-rlhf-cn, stack-exchange-paired. |
| Code | Fine-tuning | code-alpaca-en, 🔥leetcode-python-en, 🔥codefuse-python-en, 🔥codefuse-evol-instruction-zh. |
| Medical | Fine-tuning | medical-en, medical-zh, 🔥disc-med-sft-zh. |
| Legal | Fine-tuning | lawyer-llama-zh, tigerbot-law-zh, 🔥disc-law-sft-zh. |
| Math | Fine-tuning | 🔥blossom-math-zh, school-math-zh, open-platypus-en. |
| SQL | Fine-tuning | text2sql-en, 🔥sql-create-context-en. |
| Text Generation | Fine-tuning | 🔥advertise-gen-zh, 🔥dureader-robust-zh. |
| Classification | Fine-tuning | cmnli-zh, 🔥jd-sentiment-zh, 🔥hc3-zh, 🔥hc3-en. |
| Quantization Assist | Quantization | pileval. |
| Other | Fine-tuning | finance-en, poetry-zh, webnovel-zh, generated-chat-zh, cls-fudan-news-zh, ner-jave-zh. |
| Vision | Fine-tuning | coco-en, 🔥coco-en-mini, coco-en-2, coco-en-2-mini, capcha-images. |
| Audio | Fine-tuning | aishell1-zh, 🔥aishell1-zh-mini. |
Supported Technologies
| Technology Name |
|---|
| 🔥LoRA: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS |
| 🔥LoRA+: LoRA+: Efficient Low Rank Adaptation of Large Models |
| 🔥GaLore:GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection |
| 🔥LISA: LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning |
| 🔥UnSloth: https://github.com/unslothai/unsloth |
| 🔥LLaMA PRO: LLAMA PRO: Progressive LLaMA with Block Expansion |
| 🔥SCEdit: SCEdit: Efficient and Controllable Image Diffusion Generation via Skip Connection Editing < arXiv \ |
| 🔥NEFTune: Noisy Embeddings Improve Instruction Finetuning |
| LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models |
| Adapter: Parameter-Efficient Transfer Learning for NLP |
| Vision Prompt Tuning: Visual Prompt Tuning |
| Side: Side-Tuning: A Baseline for Network Adaptation via Additive Side Networks |
| Res-Tuning: Res-Tuning: A Flexible and Efficient Tuning Paradigm via Unbinding Tuner from Backbone < arXiv \ |
| Tuners provided by PEFT, such as IA3, AdaLoRA, etc. |
Supported Hardware
| Hardware Environment | Notes |
|---|---|
| CPU | |
| RTX 20/30/40 series, etc. | After 30 series, BF16 and FlashAttn can be used |
| Computing cards T4/V100, etc. | BF16 and FlashAttn not supported |
| Computing cards A10/A100, etc. | Support BF16 and FlashAttn |
| Huawei Ascend NPU |
Environment variables
- DATASET_ENABLE_CACHE: Enable cache when preprocess dataset, you can use
1/Trueor0/False, defaultFalse - WEBUI_SHARE: Share your web-ui, you can use
1/Trueor0/False, defaultFalse - SWIFT_UI_LANG: web-ui language, you can use
enorzh, defaultzh - WEBUI_SERVER: web-ui host ip,
0.0.0.0for all routes,127.0.0.1for local network only. Default127.0.0.1 - WEBUI_PORT: web-ui port
- USE_HF: Use huggingface endpoint or ModelScope endpoint to download models and datasets. you can use
1/Trueor0/False, defaultFalse - FORCE_REDOWNLOAD: Force to re-download the dataset
Other variables like CUDA_VISIBLE_DEVICES are also supported, which are not listed here.
📚 Classroom
🏛 License
This framework is licensed under the Apache License (Version 2.0). For models and datasets, please refer to the original resource page and follow the corresponding License.
📎 Citation
@misc{zhao2024swiftascalablelightweightinfrastructure,
title={SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning},
author={Yuze Zhao and Jintao Huang and Jinghan Hu and Xingjun Wang and Yunlin Mao and Daoze Zhang and Zeyinzi Jiang and Zhikai Wu and Baole Ai and Ang Wang and Wenmeng Zhou and Yingda Chen},
year={2024},
eprint={2408.05517},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2408.05517},
}